Data powers today’s digital economy and 2.5 quintillion (25 followed by 17 zeros) bytes of it is
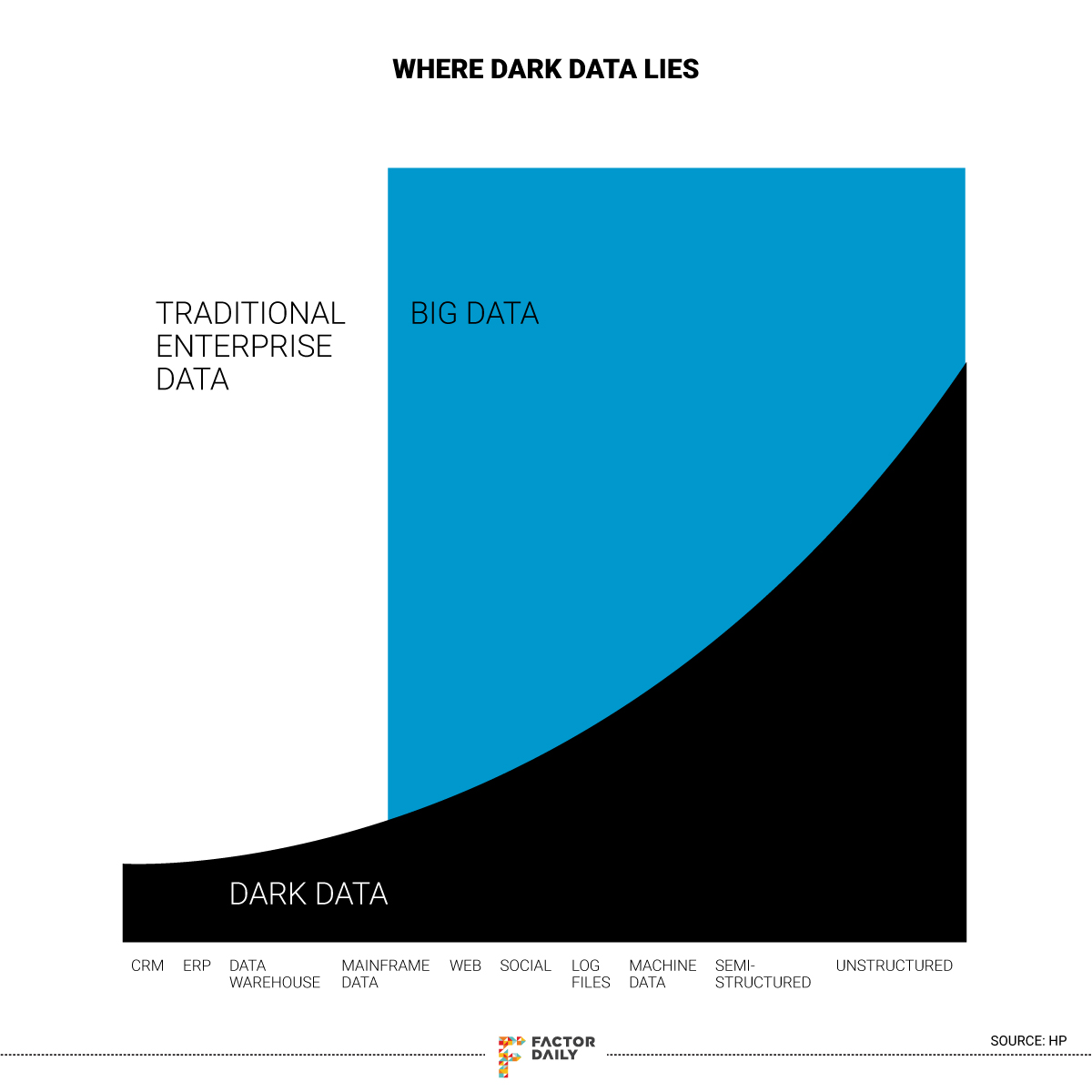
created every day. A lot of this is collected and stored by companies but they process and analyse a mere 20-25% of it. The balance remains stored in the dark recesses of a company’s system, unused, its vast potential unrealised.
So, say, a large electronics retailer deals with a dozen vendors for its products. A lot of the discussions between its procurement department and the vendors happen over email, with considerable haggling before contracts are signed. For a large retailer, it is easy for a lot of details such as offers and prices to get lost in these conversations, masking potential revenue-generating leads.
As the size of the procurements increases and the product lineup expands, potential revenue losses, too, could balloon due to the very nature of the conversations — involving trillions of bytes of untapped data. Or what’s known in the analytics industry as dark data, essentially unstructured data that companies gather through various systems and sources, both internal and external, but are not analysed. Common examples of unstructured data include emails, log files, presentations and contracts etc.
According to an
IBM report, nearly four-fifths of all available data is dark to most companies and is expected to rise to 93% by 2020. Some other estimates quote the number to be lower at 65%, but even then the amount of dark data that lie among organisations is huge.
Companies are increasingly realising the value and potential that dark data hold and seeking to mine the vast amounts of untapped information using various technologies. It hasn’t been easy. “During my interaction with the industry, I saw a lot of interest in utilising unstructured data for better decision-making. (But) all the tools and techniques currently used are not geared towards deriving value out of unstructured data,” says Partha Pratim Talukdar, a faculty member in the Department of Computational and Data Sciences (CDS) at the Indian Institute of Science (IISc) in Bengaluru. Talukdar is also the founder of artificial intelligence (AI) company Kenome Technologies that has been trying to use so-called knowledge graphs to mine dark data.
According to Talukdar, who did his post-doctoral studies at Carnegie Mellon University’s machine learning department, AI applications like deep learning and machine learning have been successful across industries but are task-driven. “You want to do a particular task, then you collect a million instances for that particular task, and then you train your model. But when you try going a little bit off, the accuracy begins to drop,” he says. “But we do not learn in that fashion. We have a good understanding of the space that we are working in and we also utilise the knowledge that we have learned over time.”
And that is the essence of Kenome. The startup utilises machine learning and natural language processing (NLP) to create knowledge graphs, which is structured data derived from a mix of structured and unstructured datasets. Or a tool to process unstructured data to generate structured data. Kenome then also creates applications based on these knowledge graphs for various uses such as customer-sensing tools to identify future demands, like what colours or features for smartphones will be the most sought after in the future, prediction engines to forecast the price of cryptocurrencies, and audit vendor retailers conversations to generate vendor income orders.
“If you already have a well-curated, normalised relational database, you have good tools right now to make sense of that. But in enterprises, 80-90% of the data is unstructured and dark in nature and that is where the tools are lacking. And we are developing for that,” says Talukdar.
The holy grail
While companies like Google, IBM and Amazon have been trying to derive value from dark data, this is yet to be tried by a lot of enterprises and non-tech focused companies as they are not yet aware of or convinced about the cost and technical effort required to invest in the process.
One of the infamous companies working in this space is Palo Alto’s Palantir, co-founded by Peter Thiel, which helps companies to intelligence agencies derive insights from a combination of structured and unstructured data. Barcelona-based Datumize, San Francisco’s Lucidworks, and Veritas from Santa Clara are some of the other international companies working in this space. In India, another Bengaluru startup Quantta is working on deriving insights from dark data held by enterprises and companies.
A frequently used analogy to explain the sheer size of unstructured data is an iceberg. Imagine an iceberg as the total amount of data an organisation has. Now the tip of the iceberg, or the part that pops out of the water and is easily visible, is the data that is used and analysed by companies in various decision-making processes and analysis. The rest of the iceberg, or the part that remains below the surface (
around 87%) and isn’t visible, is the amount of unstructured data or dark data that companies have.
“For that one-time use, you’ve generated and collected and stored it and then you never went back and looked at it. That becomes dark and you are storing that but you don’t know that you could be deriving some value out of it,” says Talukdar.
And knowledge graphs? Simply put, a knowledge graph can be thought of as an interlinked network of objects and their relationship with each other, like a knowledge base. The image below will give you an understanding of what a knowledge graph looks like.
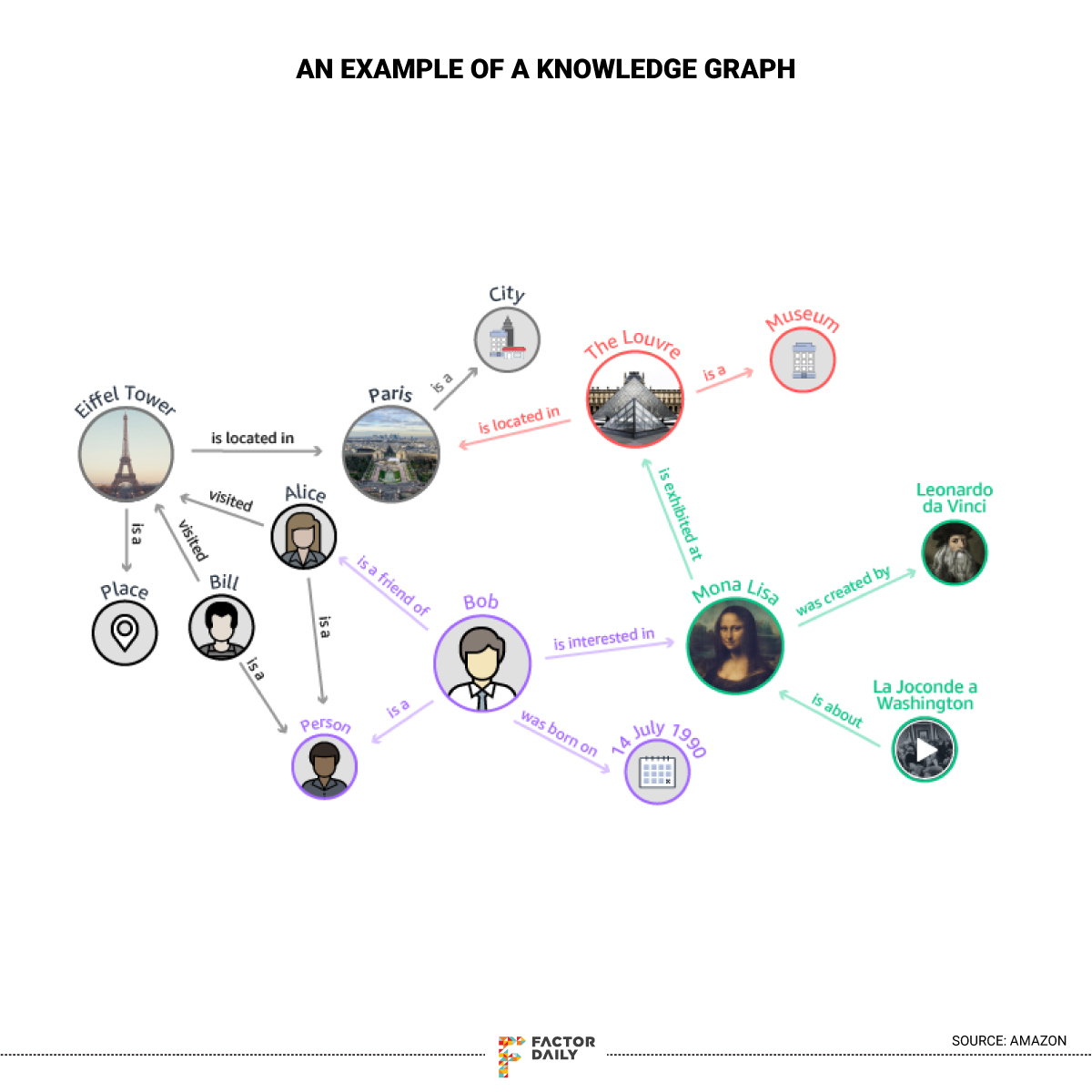
One of the most common and popular use of knowledge graphs is by Google; it is one of the core systems that power Google Search. Read
this post to know more about knowledge graphs.
Knowledge in the dark
The tech developed by
Kenome is already being deployed for various use cases, including forecasting cryptocurrency prices and generating purchase orders. At its core is the Kenome Insights Platform (KIP), which uses machine learning, deep learning, and natural language understanding to go through the unstructured data of companies to build knowledge graphs. Kenome has also built various applications that sit on KIP and provide inference capabilities over the data from companies.
One such deployment Kenome has done is at the Bengaluru-based back office of an American wholesale company with over $1 billion in annual sales. One of the processes the back office is tasked with is generating purchase orders. Talukdar did not name the client.
Although the wholesale company has an e-portal, customers find it convenient to just shoot an email or a message (unstructured data) to its sales representatives requesting items, he says. Currently, the team in Bengaluru reads those emails and messages to create purchase orders.
The SmartOrder application developed by Kenome reads the texts and is able to contextually identify products, their names, descriptions. It then generates a suggested ranked list of items based on the system’s confidence level, from which an employee can just click, choose or edit to generate purchase orders.
“The current process is very labour-intensive. What our system does is read those emails and messages automatically, cross-reference them to the company’s catalogue, and create structured purchase orders that the team can choose and confirm,” says Talukdar. “The process used to take nine minutes to generate each purchase order, which, with the help of our system, has been brought down to a two-and-half minute process.”
Kenome’s tech is also deployed at Singapore-based cryptocurrency exchange TrakInvest to predict prices for clients.
“Unlike traditional stocks, cryptocurrency prices fluctuate constantly and are often driven by news and people’s perception of the news, etc., which becomes very hard for an investor to keep track on a continuous basis and then take action in a timely manner. Our application helps with this,” says Talukdar.
The application, called SmartSense, tracks different data sources for different cryptocurrencies, which include blockchain activity, Twitter accounts, Telegram channels, forum posts, and news to derive semantic signals and use them for price prediction.
“The system enables the exchange to provide hourly as well as 24-hour predictions on the prices for their customers. Earlier, the deviation in the prediction was around $80, which our system has brought down to the $50 range,” says Talukdar.
Product-market fit prediction
Kenome’s SmartSense application is also helping a US-based company ensure that when its product hits the market it is very much in demand. Earlier, the company manually did this by reading what influencers were talking about on blogs and social media accounts.
“Once our clients sell stuff in the US but they manufacture out of China, and there is a three-month lag between those two. So they need to know in advance that three months down the line what material or colour is trending so that they can place the order for that today,” says Talukdar.
Other applications that the company has built on its Kenome Insights Platform include Smart Audit, which helps companies generate revenue from audit leads, and SmartRec, which helps companies make personalised recommendations for their customers.

Talukdar says the number of applications that can be built on the platform will grow as the type of dark datasets that the company handles changes.
“For now, our products have been able to show value to our customers and we are in the process of scaled deployments across sectors. They are generating revenue for us,” says Talukdar, whose company generated over $125,000 in revenue in 2018, its first year of operations.
Although dark data have been around for some time now, only recently have companies realised their value and begun working towards exploiting it. In 2017, Apple announced a $200-million acquisition of Lattice Data, co-founded by Stanford University professor Christopher Ré, that developed an AI-based inference system to take unstructured dark data and turn it into structured data.
Venkata Pingali, CEO of Bengaluru-based ML engineering startup Scribble Data, says the ambiguous nature of unstructured data is what makes it a challenge to develop for.
“The challenge with developing tools to deal with unstructured data is the very ambiguous nature of unstructured data. It is not easy to predict the nature of output or result. There have been continuous efforts for the past two decades but adoption has been a bit slow due to this very problem. It is also challenging to build and maintain these systems and tools,” says Pingali.
According to him, the bigger challenge is to convince companies and enterprises to put money and effort into deploying tools and systems to analyse dark data or unstructured data. “But of late, enterprise customers are beginning to understand and accept these kinds of probabilistic services and willing to invest in understanding the potential the dark data they hold have,” adds Pingali.


