If you are a toll plaza operator looking to use a computer vision-based artificial intelligence (AI) system to collect charges from highway users, you are going to run into a hurdle pretty fast. India doesn’t have a standard database that can feed that AI system. Here’s why. You decide to instal cameras that can automatically read vehicle number plates and help sync the information with your company’s database and minimise collection time. While that would roll smoothly in most developed countries, it’s easier said than done in India. Even with prescribed standards for number plate design here, many vehicles bear plates in different fonts. Result: a non-standard dataset that would make it tough for an AI system to detect from.
For AI systems to work efficiently in a particular geography, they need to be trained on a rich collection of local datasets. In India, a dearth of locally appropriate datasets is posing a big hurdle in developing a domestic AI ecosystem.
To give another example, while the Constitution of India recognizes 22 scheduled languages, there are more than a thousand dialects spoken across the country. This is a huge challenge for technology systems like speech recognition and character recognition when India is trying to go digital.
There’s also the issue of biases in AI that could occur due to a lack of properly curated local datasets. Ambitious AI projects in the West, too, are plagued with this problem. In India, the possibility is very real in the absence of locally and carefully curated data, the lack of which, for instance, could lead to underrepresented populations.
FactorDaily has curated a list of indigenous datasets that are available for aiding with research and development in various AI-based applications. A caveat here: a few of these datasets are not frequently updated or properly labelled; some require payment. The list covers datasets from different areas and sectors. If there are other datasets available from India and missing on this list, do let us know via this form and we will update the listing.
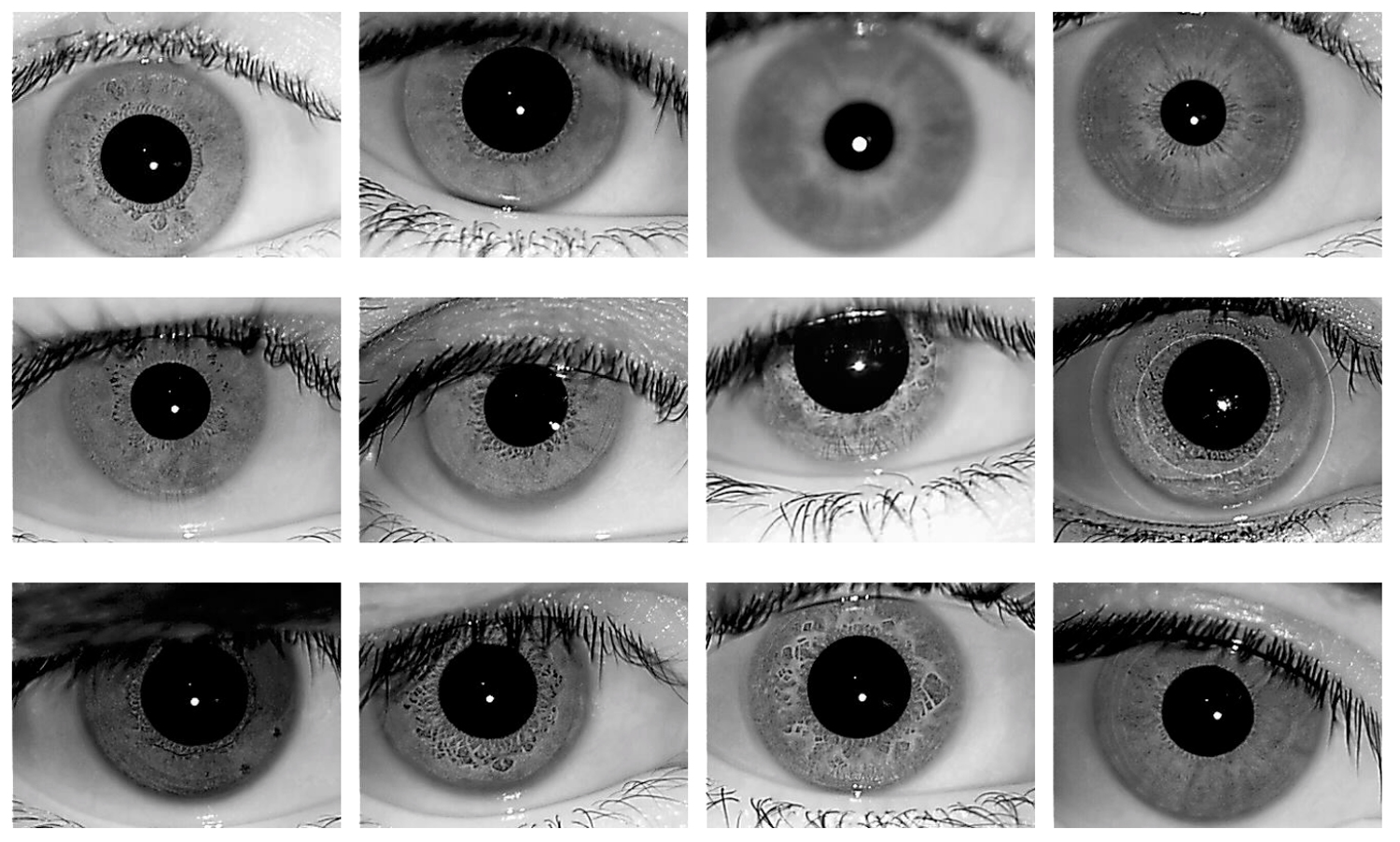
Iris image database – IIT-Delhi
This database, acquired by the Biometric Research Laboratory at IIT-Delhi, comprises iris images collected from the institute’s students and staff. The aim of the dataset is to help train and test algorithms on data from an indigenous iris database acquired in a real environment.
Ear image database – IIT-Delhi
Similar to the iris database, this database, also by the Biometrics Research Laboratory, consists of ear images of students and staff at IIT-Delhi. The aim of the database is to help support research efforts in ear biometrics.
Touchless and touch-based fingerprint database – IIT-Bombay
This database consists of fingerprint data prepared by IIT-Bombay and captured using smartphones and fingerprint scanners. The aim of the database is to help researchers compare the performance of touchless and touch-based fingerprint biometric systems.
Handwritten datasets for Indic scripts – Centre for Visual Information Technology (CVIT), IIIT-Hyderabad
This dataset comprises words handwritten in Devanagari and Telugu scripts that were curated by the Centre for Visual Information Technology (CVIT) at IIIT-Hyderabad. The aim of the dataset is to help with the development of handwritten word recognisers for these scripts.

Indic speech database – Language Technologies Research Center (LTRC), IIIT-Hyderabad
The Language Technologies Research Center at IIIT-Hyderabad provides speech and visual database of various Indic languages and scripts developed for research projects.
Word image dataset – Centre for Visual Information Technology (CVIT), IIIT-Hyderabad
This dataset consists of images of words from billboards, signboards, house numbers, house name plates, movie posters, etc. that were harvested by the Centre for Visual Information Technology (CVIT) at IIIT-Hyderabad using Google image search. This data set could be used for training or testing image or character recognition algorithms.
Multiple language datasets – Indian Language Technology Proliferation & Deployment Centre
This dataset comprises language data from 22 languages across India, including Assamese, Marathi, Bangla, Hindi, Manipuri, and Punjabi. This was curated mainly for testing Indian language support for mobile devices.
Bengali continuous speech database – IIT-Kharagpur
This database consists of unique sentences in standard Bengali colloquial language. It is curated by the Communication Empowerment Lab at IIT-Kharagpur in collaboration with Media Lab Asia. The aim of the dataset is to help with the acquisition of acoustic-phonetic knowledge and for the development and evaluation of automatic speech recognition systems.
Multiple Indian languages speech database – Microsoft Research
This database, developed by Microsoft Research, consists of conversational and phrasal speech training and test data in Telugu, Tamil and Gujarati. The aim of the dataset is to help develop systems including automatic speech recognition in these languages.
Multi variability speaker recognition database – IIT-Guwahati
This speech database, developed by IIT-Guwahati, consists of conversational and read speech in various Indian languages as well as English that were captured by multiple sensors in different environments. The aim of the dataset is to help with development and research on systems such as automatic speech recognition.
Multiple datasets – Data.gov.in, Government of India
This is the Indian government’s open government data (OGD) platform, started in 2012. It hosts data sets from various government ministries and departments but several of these are not up-to-date or properly labelled.
Satellite imagery database – Bhuvan, ISRO
This service has datasets including earth observation data from ISRO’s satellites. The data are provided via the space agency’s mapping service, Bhuvan.
Population enumeration data – Office of the Registrar General & Census Commissioner
This is a collection of large datasets provided by the Office of the Registrar General & Census Commissioner under the Ministry of Home Affairs. The datasets are from the census and cover areas such as languages, population, age, religion, disability, and schedule tribes.
City-scale road audit using deep learning dataset – Centre for Visual Information Technology (CVIT), IIIT-Hyderabad
This dataset comprises annotated data on road conditions and defects as curated by the Centre for Visual Information Technology (CVIT) at IIIT-Hyderabad.
Indian driving dataset – IIIT-Hyderabad and Intel
This dataset consists of images from cameras fixed to cars driven in and around Hyderabad and Bengaluru. With most datasets for autonomous navigation being developed on structured datasets, this dataset focuses on data from the unstructured traffic environment often found across Indian cities.
Sports (badminton) video dataset – Centre for Visual Information Technology (CVIT), IIIT-Hyderabad
This dataset, developed from badminton broadcast videos, is developed from tracking and recognizing players in each point played and annotating their playing strokes. The dataset, curated by the Centre for Visual Information Technology (CVIT) at IIIT-Hyderabad, aims to help build a system for automatic tagging of attributes and analysis of sports videos.
Financial datasets – RBI
This is a collection of datasets on various aspects of the Indian economy, banking and finance provided by the Reserve Bank of India.
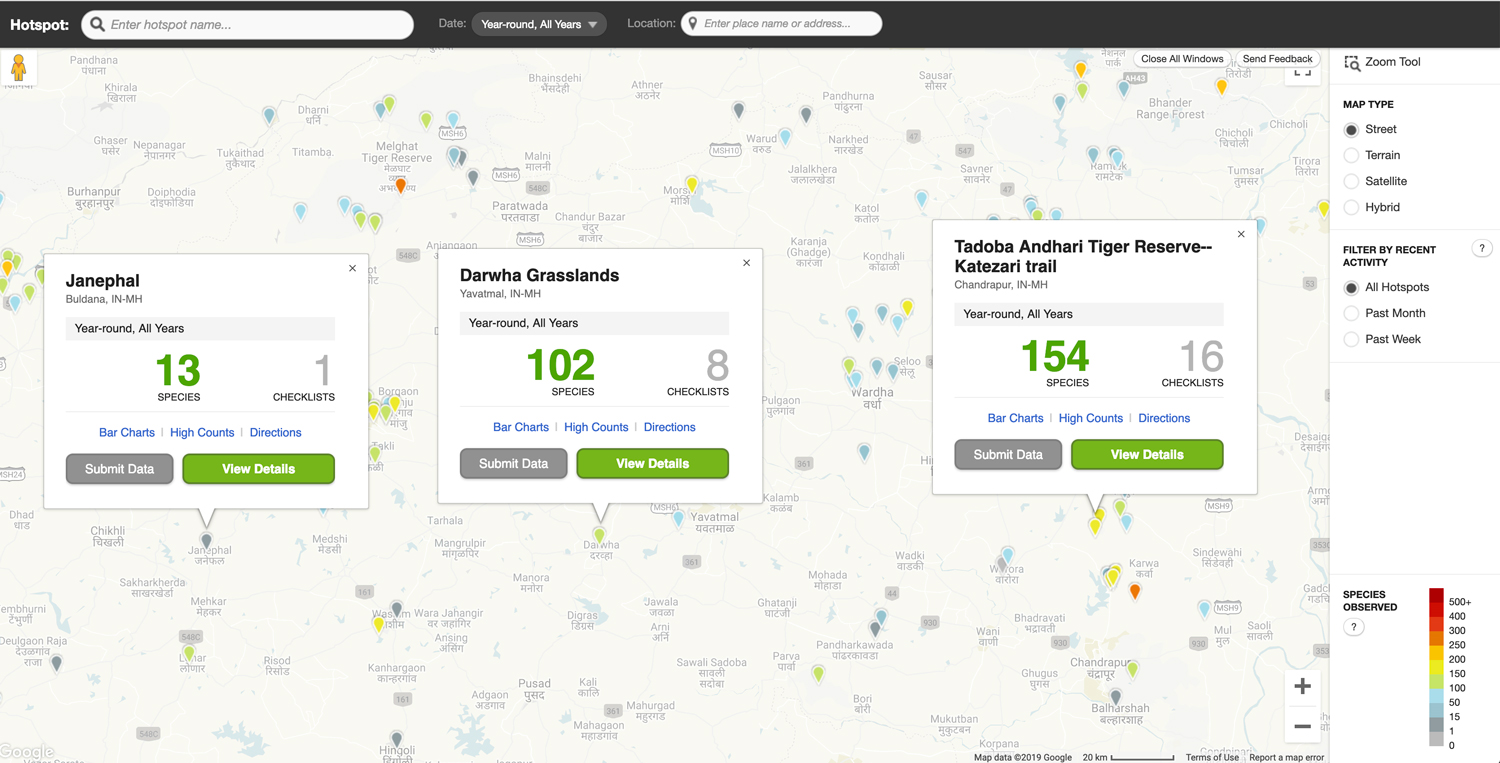
Bird data – Bird Count India
This collection of datasets pertains to the birds found in India as curated by Bird Count India, an informal collective. The data covers a range of areas including bird hotspots, images, sounds, and migration paths.